实现文本相似度算法(余弦定理)
发布于 来源 原文链接
569天前 有1个用户阅读过
于是我决定把它用到项目中,来判断两个文本的相似度。但后来实际操作发现有一些问题:直接说就是查询一本书中的相似章节花了我7、8分钟;这是我不能接受……
于是停下来仔细分析发现,这种算法在此项目中不是特别适用,由于要判断一本书中是否有相同章节,所以每两个章节之间都要比较,若一本书书有x章的话,这 里需对比x(x-1)/2次;而此算法采用矩阵的方式,计算两个字符串之间的变化步骤,会遍历两个文本中的每一个字符两两比较,可以推断出时间复杂度至少 为document1.length × document2.length,我所比较的章节字数平均在几千~一万字;这样计算实在要了老命。
想到Lucene中的评分机制,也是算一个相似度的问题,不过它采用的是计算向量间的夹角(余弦公式),在google黑板报中的:数学之美(余弦定理和新闻分类) 也有说明,可以通过余弦定理来判断相似度;于是决定自己动手试试。
首相选择向量的模型:在以字为向量还是以词为向量的问题上,纠结了一会;后来还是觉得用字,虽然词更为准确,但分词却需要增加额外的复杂度,并且此项目要求速度,准确率可以放低,于是还是选择字为向量。
然后每个字在章节中出现的次数,便是以此字向量的值。现在我们假设:
章节1中出现的字为:Z1c1,Z1c2,Z1c3,Z1c4……Z1cn;它们在章节中的个数为:Z1n1,Z1n2,Z1n3……Z1nm;
章节2中出现的字为:Z2c1,Z2c2,Z2c3,Z2c4……Z2cn;它们在章节中的个数为:Z2n1,Z2n2,Z2n3……Z2nm;
其中,Z1c1和Z2c1表示两个文本中同一个字,Z1n1和Z2n1是它们分别对应的个数,
最后我们的相似度可以这么计算: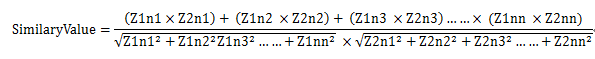
程序实现如下:(若有可优化或更好的实现请不吝赐教)
public class CosineSimilarAlgorithm {
public static double getSimilarity(String doc1, String doc2) {
if (doc1 != null && doc1.trim().length() > 0 && doc2 != null
&& doc2.trim().length() > 0) {
Map<Integer, int[]> AlgorithmMap = new HashMap<Integer, int[]>();
//将两个字符串中的中文字符以及出现的总数封装到,AlgorithmMap中
for (int i = 0; i < doc1.length(); i++) {
char d1 = doc1.charAt(i);
if(isHanZi(d1)){
int charIndex = getGB2312Id(d1);
if(charIndex != -1){
int[] fq = AlgorithmMap.get(charIndex);
if(fq != null && fq.length == 2){
fq[0]++;
}else {
fq = new int[2];
fq[0] = 1;
fq[1] = 0;
AlgorithmMap.put(charIndex, fq);
}
}
}
}
for (int i = 0; i < doc2.length(); i++) {
char d2 = doc2.charAt(i);
if(isHanZi(d2)){
int charIndex = getGB2312Id(d2);
if(charIndex != -1){
int[] fq = AlgorithmMap.get(charIndex);
if(fq != null && fq.length == 2){
fq[1]++;
}else {
fq = new int[2];
fq[0] = 0;
fq[1] = 1;
AlgorithmMap.put(charIndex, fq);
}
}
}
}
Iterator<Integer> iterator = AlgorithmMap.keySet().iterator();
double sqdoc1 = 0;
double sqdoc2 = 0;
double denominator = 0;
while(iterator.hasNext()){
int[] c = AlgorithmMap.get(iterator.next());
denominator += c[0]*c[1];
sqdoc1 += c[0]*c[0];
sqdoc2 += c[1]*c[1];
}
return denominator / Math.sqrt(sqdoc1*sqdoc2);
} else {
throw new NullPointerException(
" the Document is null or have not cahrs!!");
}
}
public static boolean isHanZi(char ch) {
// 判断是否汉字
return (ch >= 0x4E00 && ch <= 0x9FA5);
}
/**
* 根据输入的Unicode字符,获取它的GB2312编码或者ascii编码,
*
* @param ch
* 输入的GB2312中文字符或者ASCII字符(128个)
* @return ch在GB2312中的位置,-1表示该字符不认识
*/
public static short getGB2312Id(char ch) {
try {
byte[] buffer = Character.toString(ch).getBytes("GB2312");
if (buffer.length != 2) {
// 正常情况下buffer应该是两个字节,否则说明ch不属于GB2312编码,故返回'?',此时说明不认识该字符
return -1;
}
int b0 = (int) (buffer[0] & 0x0FF) - 161; // 编码从A1开始,因此减去0xA1=161
int b1 = (int) (buffer[1] & 0x0FF) - 161; // 第一个字符和最后一个字符没有汉字,因此每个区只收16*6-2=94个汉字
return (short) (b0 * 94 + b1);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return -1;
}
}程序中做了两小的改进,以加快效率:
1. 只将汉字作为向量,其他的如标点,数字等符号不处理;
2. 在HashMap中存放汉字和其在文本中对于的个数时,先将单个汉字通过GB2312编码转换成数字,再存放。
最后写了个测试,根据两种不同的算法对比下时间,下面是测试结果:
余弦定理算法:doc1 与 doc2 相似度为:0.9954971, 耗时:22mm
距离编辑算法:doc1 与 doc2 相似度为:0.99425095, 耗时:322mm
可见效率有明显提高,算法复杂度大致为:document1.length + document2.length。-- The End --